
How I Built a Memory Layer for My AI Coding Sessions
Why I built recuerd0, a context memory layer for AI coding agents, on SQLite and FTS5 full-text search instead of embeddings, vector databases, or RAG.
When I started using AI to write everyday code more than a year ago, my speed shipping features increased substantially. Then I hit the next problem — I needed a way to capture knowledge and context about features, about specific slices of the application, so I didn’t have to re-explain on every session what the functionality was about, the gotchas, the design decisions behind it. Working with a team made the need even more visible.
At first I wrote synthesized guides in Obsidian and copy-pasted them into my coding sessions. When the team needed access to the same context, we added a docs/ folder with markdown files committed in the repo. I wrote about that workflow here.
It worked well, for a while. The problem was the documents went stale. The code moved on, the decisions got revised, the docs stayed where they were. A markdown file frozen in time isn’t context — it’s archaeology.
That’s when I started playing with the idea of a context memory layer outside the app, connected to my AI agent through a CLI and a skill. That’s how recuerd0.ai was born.
Why I didn’t use RAG
This is the question I get asked most, so it’s worth answering directly.
When I started designing recuerd0, the default assumption everywhere was that any memory system needs embeddings, a vector database, and some kind of RAG pipeline. I went the opposite direction. No embeddings. No vector database. SQLite with FTS5 full-text search, exposed to the agent through a filesystem-style API — glob, grep, ranged reads — the same primitives the agent already knows how to use against a real filesystem.
The reason was practical. I’d watched how Claude Code drives a codebase. It doesn’t embed anything. It greps. It tails. It opens a file at a specific line range. The agent is good at this — it picks queries, refines them, decides when it has enough. Building an entire RAG stack just to recreate something the agent does well natively felt like solving the wrong problem.
A few weeks after I’d made that decision, Boris Cherny, the creator of Claude Code, posted that early Claude Code actually tried RAG with a local vector database — and abandoned it. Agentic search outperformed RAG “by a lot,” with fewer issues around security, privacy, staleness, and reliability. A few weeks after that, GitHub Copilot shipped a memory system that uses just-in-time citation verification, not embeddings. Two of the most well-resourced AI coding teams in the world had independently arrived at the same conclusion.
The failure modes Boris listed map cleanly to what recuerd0 already had:
- Security. No embeddings leaving the server, no third-party embedding API.
- Privacy. Content stays as markdown in SQLite. No opaque vector representation of your team’s knowledge sitting in a separate store.
- Staleness. The FTS5 index updates on write via an
after_savecallback. No re-embedding pipeline, no sync lag. - Reliability. Deterministic. Search “authentication” and you get documents containing “authentication” — not a cosine-similarity guess.
- Simplicity. No embedding model dependency, no vector DB to operate, no chunking strategy to tune.
The other thing I liked about this approach is what I’d call the bitter-lesson angle. Agentic search keeps the intelligence in the model. As Claude and other agents get smarter, retrieval gets better for free. RAG quality, by contrast, depends on continuous engineering effort — re-chunking, re-embedding, tuning similarity thresholds. I’d rather bet on the model side of the stack than maintain a pipeline that needs constant care.
There’s a counter-argument worth naming: for true concept search across a 500K-line codebase you’ve never read, vector similarity has a real edge. Recuerd0 isn’t a codebase search tool — it’s a curated knowledge base where a workspace holds 5–50 intentional memories, not 50,000 auto-indexed chunks. At that scale, FTS5 isn’t just sufficient — it’s optimal.
How I actually use it
The agent does most of the work. I don’t write memories by hand and I don’t tell the agent where to look. I let it decide.
Before I start a feature, in planning mode, I ask:
Search and grep memories that might be helpful for the task at hand.
The agent runs glob and grep against the workspace, pulls in the few memories that are actually relevant, and surfaces the decisions and constraints I’ve already made. No copy-paste from Obsidian, no digging through a docs folder.
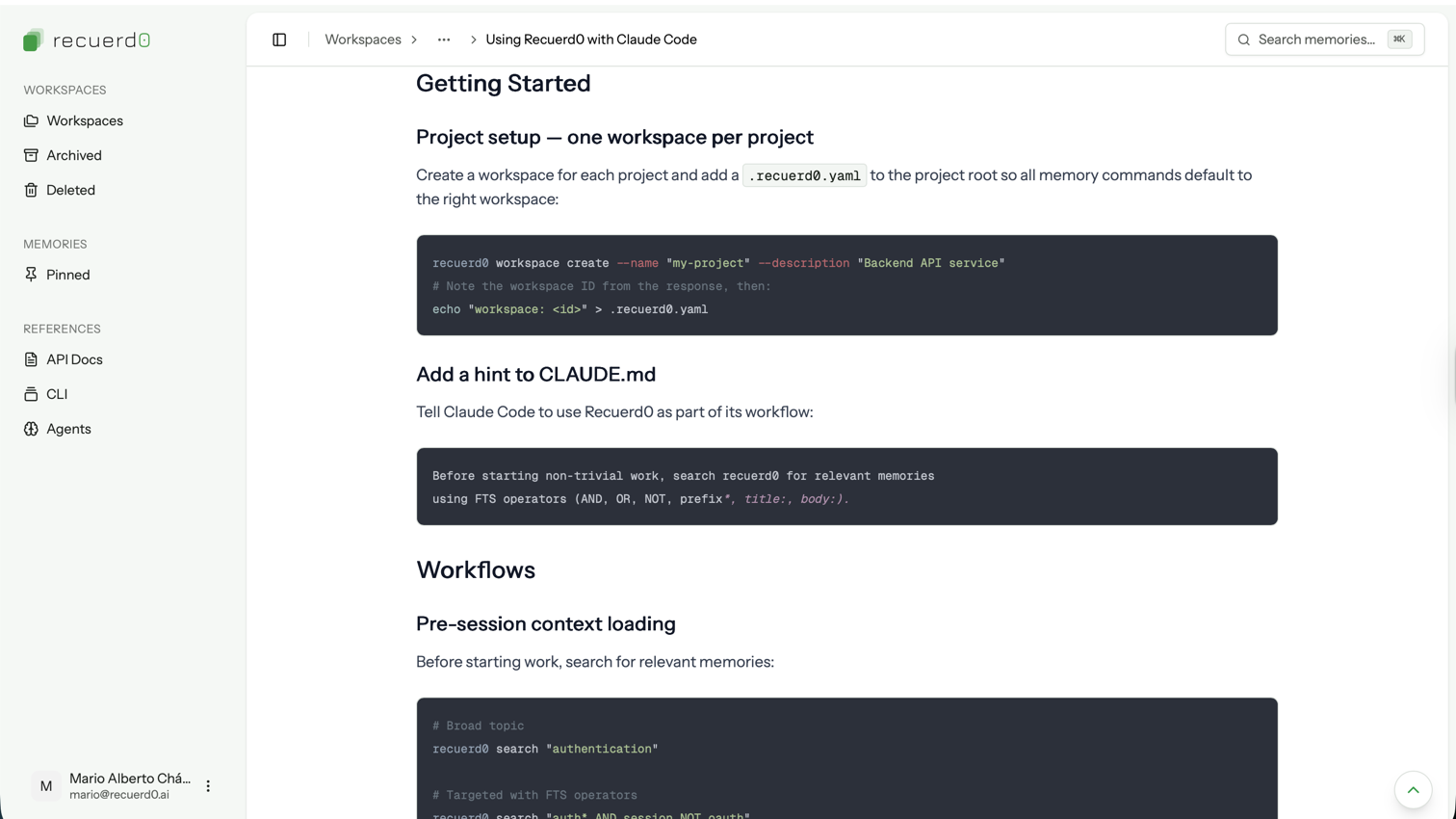
When I finish a feature and commit, I ask:
Do we have any learnings from this session that we need to persist as memory?
The agent evaluates what’s new, decides which memories should be created, categorizes them — decision, discovery, preference, general — and links them to existing memories. If something contradicts what was already stored, it updates the existing memory rather than creating a duplicate. Stale memories don’t accumulate, because new sessions either reinforce them or update them.
The categorization and linking aren’t features I built for myself to use manually. They’re features the agent uses on my behalf. I’m not curating a knowledge graph by hand; the agent is, with me approving the calls it makes.
I do the same thing the agent does — but it does it faster and more consistently than I would.
What this changed
Three things I didn’t expect when I started.
The first is that I stopped writing documentation as a separate task. Every coding session ends with a “what should we remember” step, and that step is the documentation. The docs are no longer a parallel artifact that drifts out of sync — they’re a byproduct of the work.
The second is that the team benefits more than I expected. Memories from one engineer’s session are immediately searchable by another. The cross-workspace links mean that decisions made in one slice of the app surface in another when relevant. The repo’s docs/ folder used to be a shared resource that nobody actually maintained. Recuerd0 became a shared resource that maintains itself, because every session adds to it.
The third is the meta-thing about AI tooling that I keep coming back to: the model is rarely the bottleneck. The model is excellent. What’s missing is the harness around it — the integrations, the memory, the conventions, the workflow. Recuerd0 is the piece of harness I needed. Yours might be different. But the pattern of “give the agent simple, deterministic primitives and let it drive” is the part I’d recommend regardless of what you end up building.
If you want to try recuerd0, it’s free to self-host or $15/month managed at recuerd0.ai. The CLI is documented here and the agent skill here.