
From context engineering to Recuerd0
The layered documentation workflow I described in January revealed a deeper problem — and became a product. How context engineering needs led to building Recuerd0, a versioned knowledge base for AI tool context.
The layered documentation workflow I described in January revealed a deeper problem — and became a product.
In January, I wrote about how I actually use AI to write Ruby on Rails code. The core idea was that context is everything. Without layered documentation — technical foundation, pattern synthesis, feature guides, implementation specs — AI-generated code is unreliable. With it, you get code you can actually ship.
That post resonated with many people. But something kept bothering me after I published it.
The problem behind the problem
The workflow I described works. I’ve used it to deliver features to both brownfield and greenfield production applications. The documentation layers are the difference between useful AI output and confident nonsense.
But maintaining those documents became a problem in itself.
I started using Obsidian to organize them. It was a natural fit — markdown files, local-first, good search. For a while, it worked well enough. But as I added more projects and started collaborating with other people, things got complicated.
Some documents needed to live in a project repository so the rest of the team could access them. Others needed to stay in Obsidian because they referenced knowledge across multiple projects — patterns I use everywhere, not just in one codebase. I ended up with documents split between Obsidian vaults, Git repos, and local folders, each with its own version of the truth.
And the documents aren’t static. Architecture evolves. You switch from one approach to another. You update a pattern document to reflect the new convention, but the context for why it changed is lost. Three months later, someone reads the document and doesn’t know if the current version reflects a deliberate decision or if someone just forgot to update the old guidance. There’s no history, no rationale trail.
On top of all that, I was using Claude Code while other engineers on the team were using Cursor. Sharing the documents was harder than it should have been — different tools expect different formats, different file locations, different configuration conventions. The knowledge was the same, but getting it into each person’s tool was manual work that nobody wanted to do.
I was spending real time on a problem that shouldn’t exist: keeping project knowledge organized, versioned, and accessible to both people and tools across projects.
The realization
The Obsidian experience clarified something for me. The problem wasn’t Obsidian — it’s a great tool for thinking and writing. The problem was that I was using a personal knowledge tool for something that needed to be infrastructure: versioned, shared, accessible by both humans and machines, with a history of why things changed.
Context engineering — curating the background knowledge that makes AI tools useful — has become a core developer skill. But there are no dedicated tools for it. We have IDEs for writing code, Git for versioning code, and CI/CD for deploying code. To manage the knowledge that AI tools consume, we have scattered Markdown files across different locations and copy-paste between them.
On top of that, every AI tool has its own configuration format. MEMORY.md, .cursorrules, AGENTS.md — knowledge prepared for one tool doesn’t transfer to another. You end up maintaining parallel versions of the same conventions, and they drift apart.
I started looking at what people in the community were building. Developers spending months wiring Obsidian vaults to Claude Code with custom hooks and 2,000-line CLAUDE.md files. Platform vendors are adding proprietary memory features that lock your knowledge inside their product. Impressive engineering, but the approaches share the same flaw: they’re either fragile, locked to one tool, or both.
What I wanted was simpler. A server I could point any tool at. Versioned markdown that tracks how project knowledge evolves — and why. A REST API that doesn’t care whether the client is Claude Code, Cursor, a shell script, or a CI pipeline. Something that makes cross-project knowledge possible without splitting documents across vaults and repos.
So I built it.
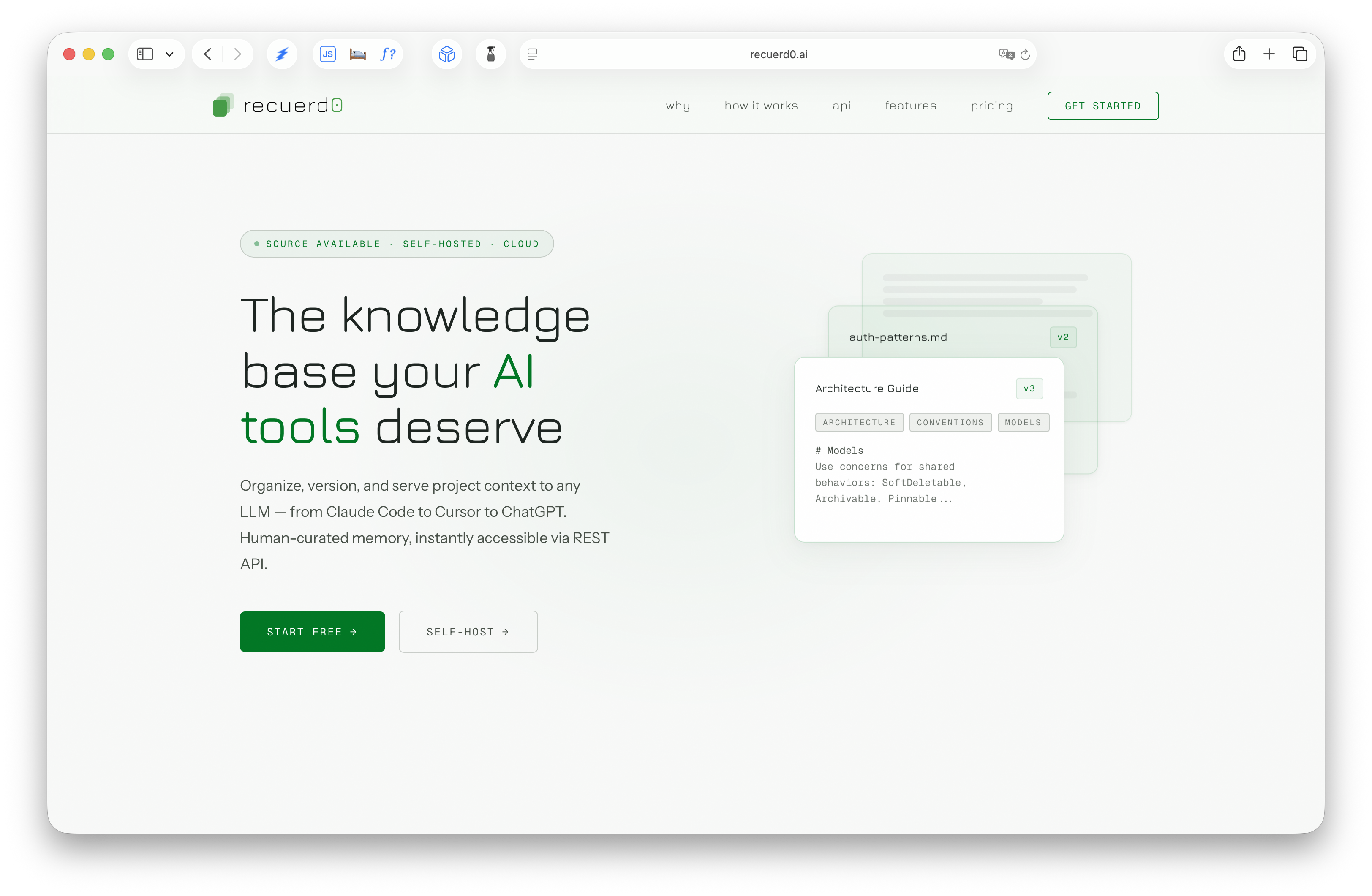
Building Recuerd0
I used the same flow I described for greenfield applications. MVP document first — the application I wanted, the stack, the features that mattered. Brand design. Implementation specs with visual mocks. Claude Code for implementation, with the documentation layers keeping the generated code consistent.
It was a good test of my own methodology. The layered documentation workflow produced the tool that makes layered documentation easier to manage. There’s a circularity to it that I appreciate.
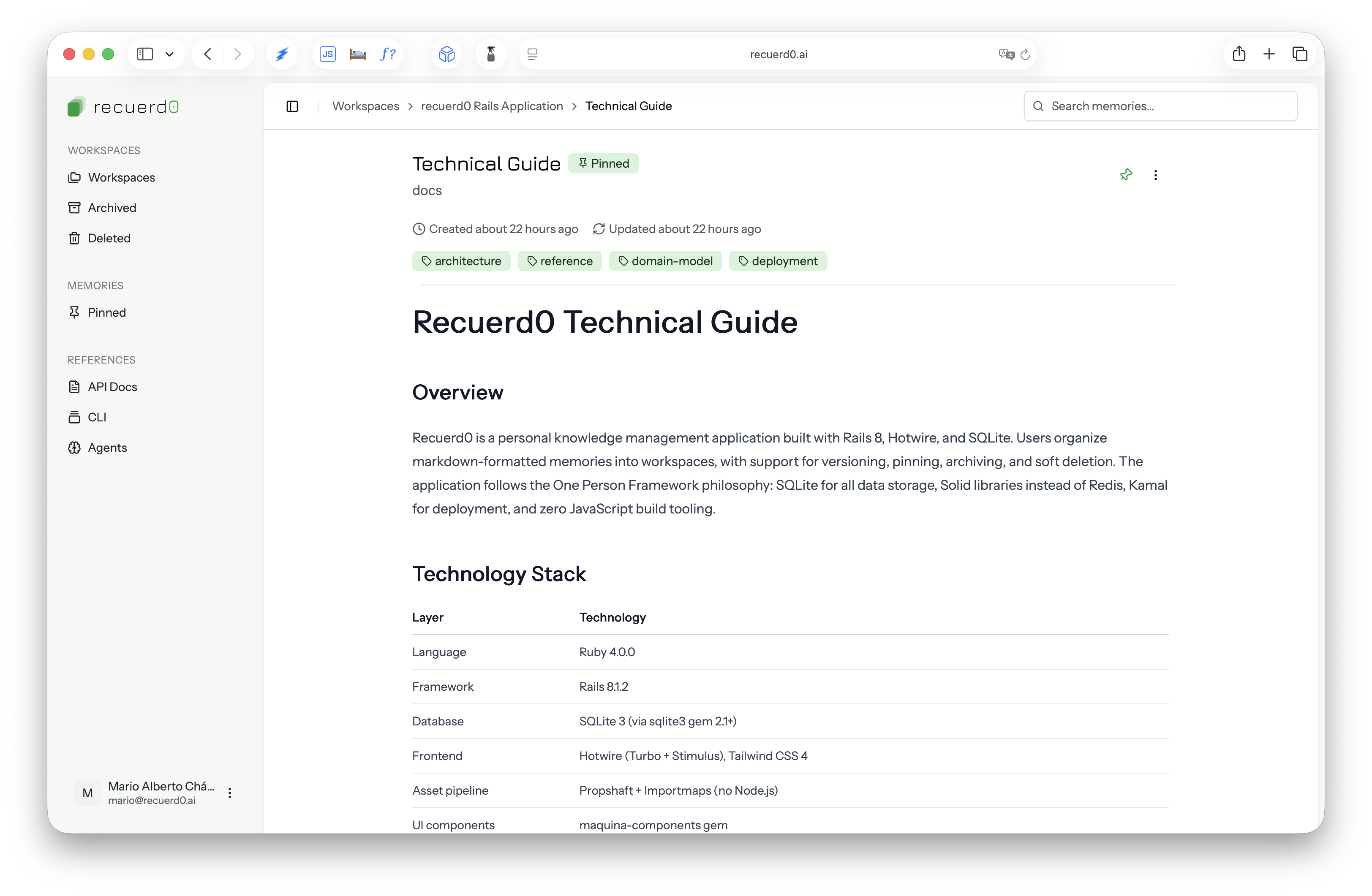
Recuerd0 is a knowledge base for the AI tool context. You organize project knowledge into workspaces — one per project, one per domain, whatever grouping makes sense. Inside each workspace, you write versioned markdown memories: your architecture decisions, naming conventions, deployment patterns, and the reasons behind your technical choices. Then you serve them to any AI tool via REST API.
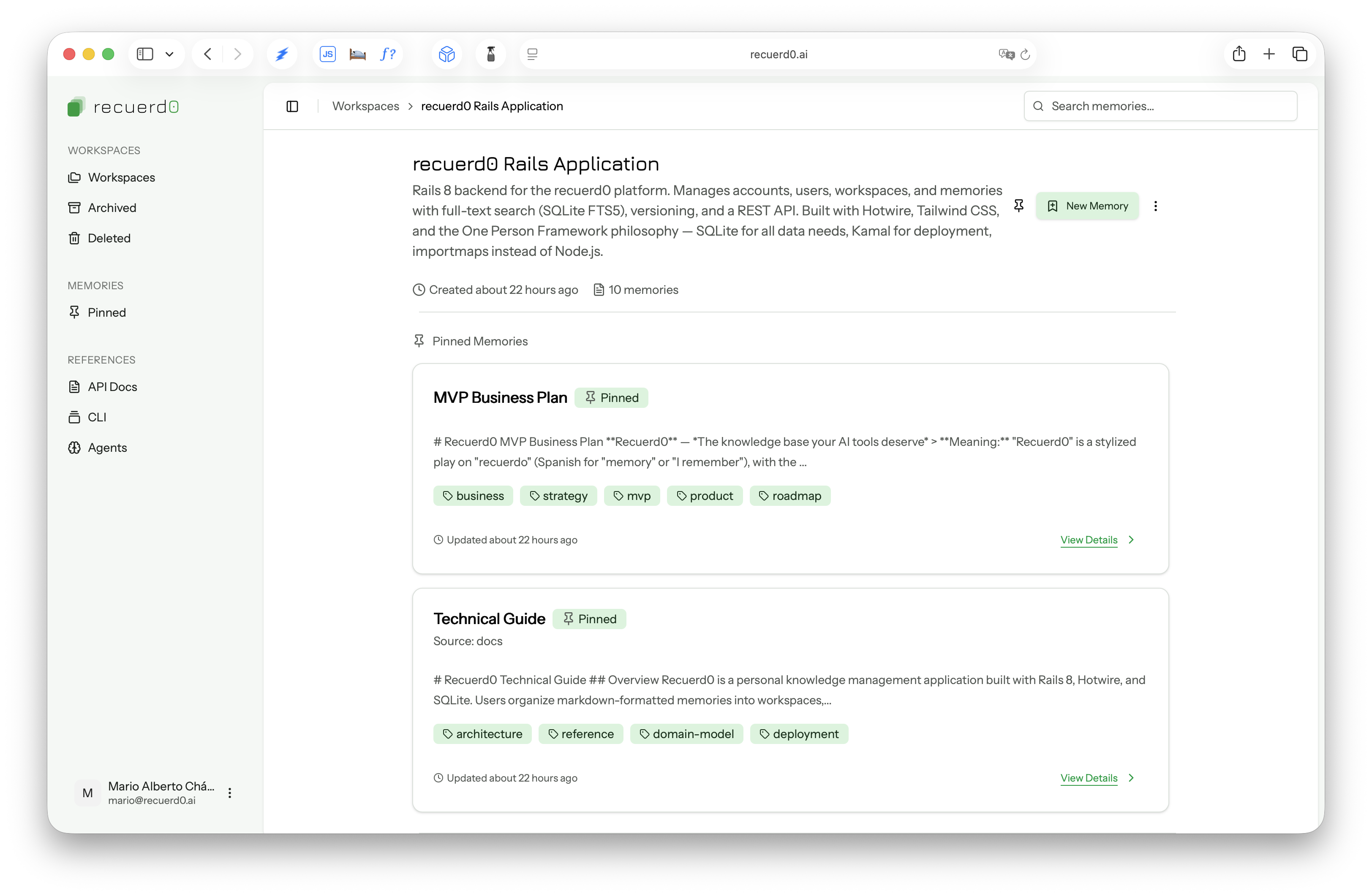
The search uses SQLite FTS5, which turned out to be the right architectural choice. The Claude Code team recently shared that they moved away from RAG and embedding-based search in favor of agentic search — where the model decides what to look for and refines its queries. FTS5 is exactly the right primitive for that pattern: deterministic, fast, no embedding infrastructure to maintain.
The whole stack is Rails 8, SQLite, and Docker. No external services, no data leaving your server, minimal dependencies. It’s the same philosophy I apply to everything I build with Maquina: practical simplicity.
Making it sustainable
Building a tool is one thing. Sustaining it is another.
Recuerd0 SaaS is $15/month for up to 10 users. Managed hosting, automatic backups, updates, and email support. The subscription directly funds ongoing development — new features, CLI improvements, better documentation, and more agent integrations. If you want the simplest path to start using Recuerd0, this is it.
But I’m not interested in locking anyone in. The last thing I want is to build a tool about knowledge portability that traps people on my platform.
I’m working on getting the source code ready for self-hosting. When it’s available, it will be under the OSASSY license — essentially MIT with one addition: you can’t take the code and offer it as a competing hosted service. This is the same model 37signals uses for Fizzy. Use it, modify it, deploy it on your own server — free forever. You just can’t resell it as SaaS.
I chose OSASSY because it aligns with how I think about open source sustainability. The code should be available. People should be able to self-host. But the hosted version needs to be viable as a business, or there won’t be anyone maintaining the project in six months. This license makes both possible without the tension that comes from more restrictive models.
In the meantime, Recuerd0 Cloud is live and ready. And when the self-hosted option ships, your data and workflows will transfer directly — same API, same format, same everything.
What I learned
Building Recuerd0 reinforced something I said in the January post: being a great communicator matters more than being a fast coder. The most important work I did wasn’t writing Ruby — it was deciding what knowledge is worth capturing, how to structure it, and how to make it accessible.
The same principle applies to using Recuerd0. The tool doesn’t tell you what to write. It gives you a place to put it, a way to version it, and an API to serve it. The intelligence — what matters about your project, which conventions are worth codifying, when a decision has evolved enough to warrant a new version — that stays with your team.
I think that’s the right balance. The humans curate. The software serves. Your AI tools get reliable, consistent context every time they start a session.
If you’ve been maintaining context documents the way I described in January, and you’re tired of keeping parallel versions in sync across tools, give it a try. Self-hosting is coming — nobody gets locked in.
Context engineering deserves a dedicated tool. This is mine.