
Lecciones construyendo un API REST
Durante el 2019 un equipo de ingeniería de micheda.io estuvo enfocado en el desarrollo de un producto interno que lleva por nombre Creditar.io. Desde su concepción, Creditar.io estuvo diseñado para ser una plataforma a través de la cual empresas FinTech pudieran configurar sus flujos y procesos libremente y olvidarse de desarrollar su propio motor bancario y enfocarse en la parte importante de su negocio.
Lecciones construyendo un API REST
Durante el 2019 un equipo de ingeniería de micheda.io estuvo enfocado en el desarrollo de un producto interno que lleva por nombre Creditar.io.
Creditar.io es un motor bancario que cuenta con la siguiente funcionalidad.
- Manejo de solicitudes de crédito
- Expedientes de clientes
- Flujo de pre-calificación de solicitudes
- Administración de créditos
- Gestión de pagos
- Manejo de portafolio de préstamos
- Gestión de campañas de Crowdfunding
Desde su concepción, Creditar.io estuvo diseñado para ser una plataforma a través de la cual empresas FinTech pudieran configurar sus flujos y procesos libremente y olvidarse de desarrollar su propio motor bancario y enfocarse en la parte importante de su negocio.
Debido a esto, tomamos varias decisiones técnicas que nos llevarán a que Creditar.io fuese una plataforma sobre la cual construir otras aplicaciones o servicios. Algunas de las decisiones fueron las siguientes.
- Una instancia privada de aplicación y base de datos por cada cliente; además de datos sensibles cifrados a nivel de base de datos.
- Flexibilidad desde la UI de Creditar.io para poder configurar diferentes productos crediticios en diferentes escenarios.
- Notificar a través de WebHooks de diferentes acciones manuales y automáticas en la plataforma.
- Flexibilidad para que la FinTech defina su flujo de recolección de información del cliente y aplique sus propias validaciones de información.
- Toda la operación de Creditar.io se expone a través de un API REST 100% documentada.
Como equipo de diseño y desarrollo hemos tratado de poner nuestra experiencia junto con la asesoría - y desilusión de sus plataformas actuales - que recibimos sobre la operación de empresas FinTech amigas.
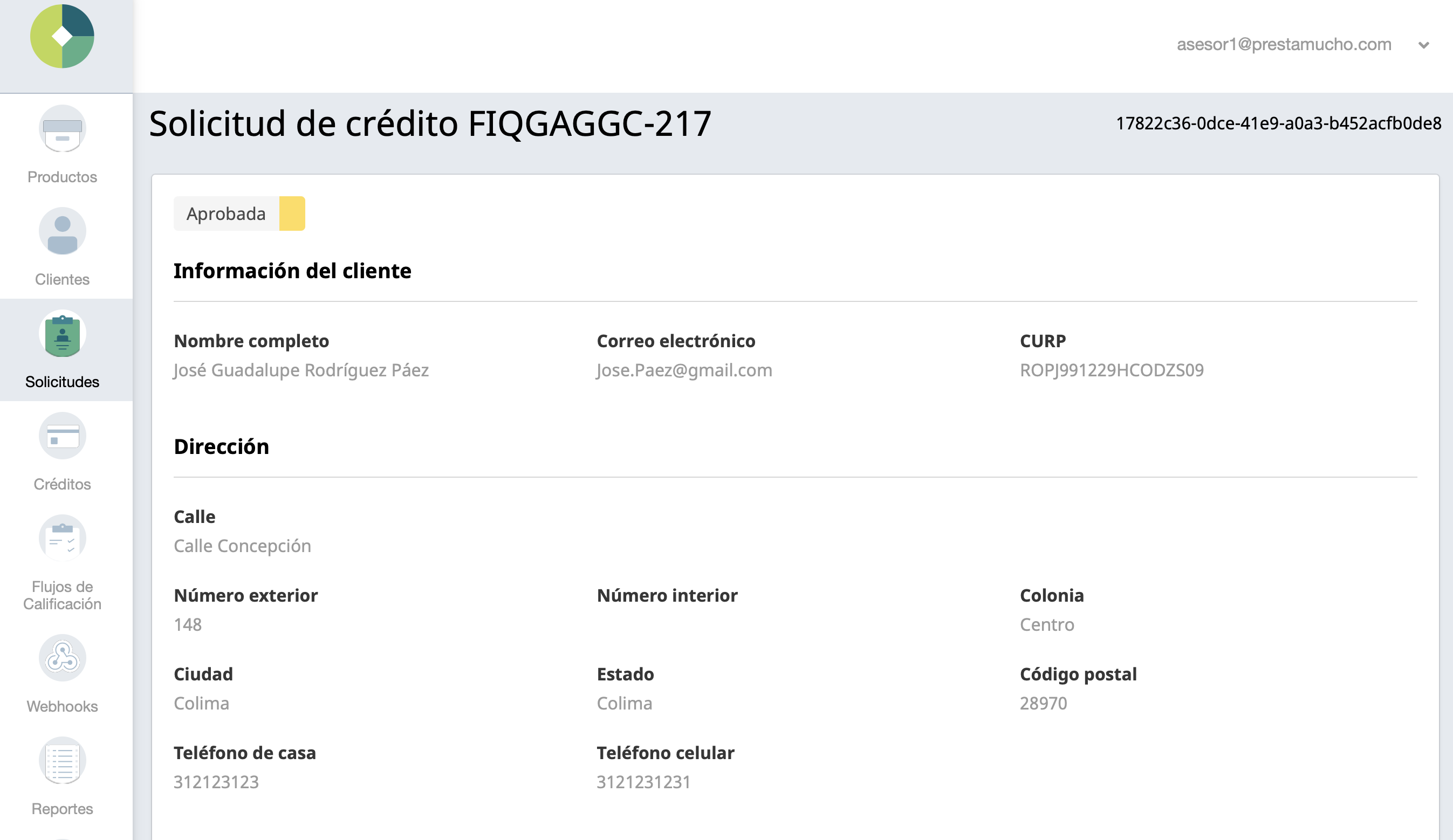
El API era una parte crucial en cómo podíamos ayudar a otras empresas a no pensar en Creditar.io y que se pudieran enfocar en la parte relevante de sus servicios. Es por eso que me voy a enfocar el resto de este post en las lecciones y decisiones que tomamos al construir el API.
API REST
Cuando comenzábamos a tomar decisiones de cómo debería ser el API. Se tomó en consideración el que fuera un GraphQL API pero fue un poco complicado el darle sentido de esta forma. Si bien GraphQL ofrece una serie de mejoras en cómo comunicarse entre servicios vía Internet, para nuestro caso en particular no se observaba una ventaja real el seguir por este camino.
Así que la decisión recayó en un API REST. Primeramente el API REST sigue los estándares de HTTP los cuales son estables y documentados desde la versión 1 en 1990, después en 1997 con la versión 1.1 y finalmente en el 2015 con la versión 2.
HTTP/2 trae consigo mejoras que, aunque lentamente, se han ido integrando en Web Servers y herramientas de desarrollo. Estos son algunos de los beneficios.
- Compresión de los Headers: Los metadatos enviados en una solicitud o respuesta pueden llegar a ser más grandes en tamaño que el contenido del mensaje en algunos casos.
- Comunicación dos vía o Multiplexación: Con una sola conexión es posible mandar varias solicitudes y obtener varias respuestas, evitando el tener que cerrar y abrir una conexión por cada recurso realizando cada ocasión un Handshake que es costoso. Inclusive el servidor puede decir hacer un “Push” de recursos no solicitados pero que serán útiles más adelante.
- Contenido binario: El contenido del cuerpo del mensaje va en formato binario, una vez más, reduciendo el tamaño los mensajes enviados entre el cliente y servidor.
- Cifrado de conexión: Si bien HTTP/2 no requiere comunicación vía TLS, es una tendencia que va de la mano para soportar HTTP/2 en los Servidores Web y los clientes.
Si bien el estándar no está totalmente implementado en todas por todas las partes involucradas, hoy en día y casi sin mayor esfuerzo es posible obtener sus beneficios, por ejemplo, utilizando servicios como Cloudflare o bien poniendo la aplicación detrás de NGNIX con el soporte para HTTP/2 activo.
En el caso de los clientes para consumir el API, dependiendo del lenguaje desde dónde se consuma hay opciones para obtener algunos de los beneficios de HTTP/2, por ejemplo en Ruby el cliente HTTPX permite hoy en día algunos de esos beneficios.
Tomando en cuenta lo antes mencionado y la experiencia previa trabajando en la implementación de APIs para diferentes tipos de aplicaciones la realidad es que difícil construir un API REST bien diseñada y que no terminemos odiando más adelante en el camino. Es todavía más difícil cuando quien la construye o la consume no conoce del estándar HTTP.
Básicos de HTTP
A final de cuentas trabajar en un API REST no es otra cosa entender que un servidor puede recibir una solicitud y debe de proporcionar una respuesta; ya sea en una conexión única o multiplexada.
Así se ve una solicitud.
GET /clients?page=1 HTTP/1.1
Host: creditar.io
Authorization: Bearer hdue373nd393mk38304k
Accept: application/json
La respuesta para la solicitud anterior es algo parecido a lo siguiente.
HTTP/1.1 200 OK
Content-Type: application/json
Cache-Control: no-cache, private
Location: https://creditar.io/clients?page=1
Connection: close
{ "data": { "id":: 636264b1-dc0d-453e-8804-4ac451e1dbd5 ... },
{ "id": 636264b1-dc0d-453e-8804-4ac451e1dce8 ... } ...
}
Lo que vemos en ambos casos es el protocolo de HTTP en acción.
REST
Algo que muchos damos por sentado es que entendemos que es REST y aunque el concepto es relativamente simple lo que entendemos no es necesariamente lo correcto.
En términos prácticos REST significa “Representational State Transfer”. La idea se basa en como representar un estado - el estado de un recurso o recursos - para su transferencia. REST es estilo de arquitectura de software. centrado en los recursos disponibles por el servidor.
Recurso
Un recurso es una abstracción de información, un recurso o una colección de recursos es todo lo que podemos nombrar en un sistema y a diferencia de la creencia general puede o no tener conexión directa con un modelo de datos. Por ejemplo, un cliente puede representar a un objeto que mapea a un registro a en una base de datos o bien puede representar la combinación de datos dentro de un sistema pero que hacia el exterior es mostrado como una unidad. Los recursos en un API REST están vinculados a una URL.
/clients/636264b1-dc0d-453e-8804-4ac451e1dbd5
A través de las URLs del recurso, es como en un API REST nos es posible llevar a cabo acciones que impliquen obtener más información o bien cambiar el estado del mismo.
Representación
La representación de un recurso consiste en datos y quizás metadata. No hay un estándar de cómo representar el recurso. La representación puede ser en simple texto, en XML o JSON; siendo está última la representación defacto en casi toda API actual.
Accept: application/json # Enviado por el cliente
Content-Type: application/json # Respuesta del servidor
# Representación del recurso
{ "data": { "id":: 636264b1-dc0d-453e-8804-4ac451e1dbd5 ... },
{ "id": 636264b1-dc0d-453e-8804-4ac451e1dce8 ... } ...
}
Para el caso de representación en formato JSON en contar un esquema JSON puede ser de gran ayuda tanto para quién desarrolla el API como para quién la consume. Sobre este punto vamos a hablar un poco más adelante.
REST aprovecha el HTTP
Como vemos, hay una relación intrínseca entre REST y HTTP. Los conceptos de arquitectura de REST están basados en los fundamentos del protocolo de HTTP.
Cómo tratar de escribir un buen API REST?
Ahora que homologamos un poco el conocimiento de qué es un API REST continuemos con algunos conceptos que nos ayudaran en el desarrollo de nuestra API.
Usar UUID para los recursos
Es común en los frameworks de desarrollo que los registros en la base de datos utilicen números enteros como llave primaria. Estos números se calculan al crear el registro y tienen la particularidad de ser números consecutivos.
Alguien con un poco de tiempo libre puede aprovechar esta situación tratar de adivinar los identificadores de los recursos y tratar de aprovechar posibles “hoyos” de seguridad para realizar operaciones con ellos.
Es por eso que la recomendación en este caso es utilizar “Global Unique Identifiers” o UUID, ya que estos son una cadena de texto - en realidad son varios bloques de números aleatorios en hexadecimal - indescifrable normalmente generada a partir de un generador de números aleatorios seguro.
636264b1-dc0d-453e-8804-4ac451e1dbd5
Si por ejemplo en tu actual aplicación utilizas números enteros como identificador para tus recursos, no es necesario rehacer toda esa parte de la aplicación, únicamente con agregar un campo de tipo UUID y exponer este identificador a través del API es suficiente.
Acciones REST
Es importante identificar los recursos que vamos a exponer a través de nuestro API. Como se mencionó anteriormente, los recursos expuestos por el API no necesariamente tiene una relación directa con el modelo de datos de nuestra aplicación.
Los recursos pueden tener 5 acciones básicas: Crear, Leer, Actualizar, Eliminar y Listar. Estas deben de estar organizadas alrededor del nombre del recursos, que normalmente se escribe en plural, y deben de hacer uso correcto de los Verbos de HTTP y los Estatus de respuesta.
Clients
- Create POST /clients 201
- Read GET /clients/636264b1-dc0d-453e-8804-4ac451e1dce8 200
- Update PATCH /clients/636264b1-dc0d-453e-8804-4ac451e1dce8 204
- Delete DELETE /clients/636264b1-dc0d-453e-8804-4ac451e1dce8 204
- List GET /clients 200
Si existe alguna acción no-estándar a las antes mencionadas quizás vale la pena considerarla como un recurso adicional. Por ejemplo, supongamos que necesitamos en el API las acciones para bloquear o desbloquear un cliente. Una de las forma en como he visto que se implementan este tipo de acciones es la siguiente.
PUT /block_client/636264b1-dc0d-453e-8804-4ac451e1dce8 204
PUT /unblock_client/636264b1-dc0d-453e-8804-4ac451e1dce8 204
No es muy REST, pero funciona. El problema con este tipo de implementaciones es que es muy sencillo que se salgan de control y terminemos con nuestro API lleno de acciones no REST. Otro problema que he visto es que ambas acciones para bloquear y desbloquear terminan en el código de nuestro framework en un sólo método con condicionales para ejecutar un bloqueo o un desbloqueo.
Si es realmente necesario implementar acciones como estas en el API entonces la mejor forma de implementarlo sería la siguiente.
POST /clients/636264b1-dc0d-453e-8804-4ac451e1dce8/block 201
DELETE /clientes/636264b1-dc0d-453e-8804-4ac451e1dce8/unblock 204
Sobre todo, asegurando en la implementación que cada acción quede en su propio bloque de código sin condicionales para determinar que acción realizar.
Viendo los ejemplo anteriores podemos notar que la organización de los recursos en el API no sólo implica el cómo se define la URL del recurso ya que esta organización va acompañada de la utilización adecuada de los verbos de HTTP y de los estatus de respuesta.
No hay nada más frustrante en un API que todas las llamadas se hagan con un GET o un POST y que todos los estatus de respuesta sean un 200 sin importar que acción se realizó o si ocurrió algún error.
Jerarquía de recursos
Otro punto importante a considerar cuando diseñamos un API es la jerarquía de recursos. Si consideramos que un cliente puede tener créditos y que un crédito puede tener referencias empezamos a ver una jerarquía de recursos.
La forma más común en como normalmente se resuelve esta situación es la siguiente.
# Lee los créditos de un cliente
GET /clients/636264b1-dc0d-453e-8804-4ac451e1dce8/credits
# Crea un nuevo crédito al cliente
POST /clients/636264b1-dc0d-453e-8804-4ac451e1dce8/credits
# Lee las referencias del crédito 2 del cliente 1
GET /clients/636264b1-dc0d-453e-8804-4ac451e1dce8/credits/92545809-e0e7-43df-b53e-8a7bc5eeb364/references
Si deseamos pedir una referencia en particular la URL se vuelve todavía más grande y se empieza a complicar. Técnicamente hacer esta implementación es relativamente simple; racionarla quizás no sea tan sencillo.
La solución más sencilla en este caso es limitar el anidar recursos a máximo un segundo nivel, en el peor de los casos. Lo ideal y lo que hicimos en Creditar.io fue mantener una jerarquía plana para los recursos.
# Lee los créditos de un cliente
GET /credits/?cliente_id=636264b1-dc0d-453e-8804-4ac451e1dce8
# { cliente_id: 636264b1-dc0d-453e-8804-4ac451e1dce8, ... } en el cuerpo de la solicitud indicamos el cliente
POST /credits
# Lee las referencias de un crédito
GET /references/?credit_id=172fcb04-52a5-4f5b-8bd0-2655b89d53d3
Es más sencillo el razonar el API con esta jerarquía plana; la intención de las acciones son más fáciles de vislumbrar.
Demasiadas vueltas al servidor
Una de las quejas más comunes que he escuchado de las API REST es que hay que hacer más de una solicitud a varios recursos para traer toda la información que posiblemente requiere el cliente que la está consumiendo. Desafortunadamente cada solicitud crear su propia conexión al servidor lo que a la larga hace que la respuesta final tarde tiempo.
# Solicita un cliente
GET /clients/636264b1-dc0d-453e-8804-4ac451e1dce8
# Solicita los créditos del cliente
GET /credits/client_id=636264b1-dc0d-453e-8804-4ac451e1dce8
# Solicita los pagos del de los créditos
GET /payments/credit_id=93570b12-42dc-4850-a535-16fb7aa5d0cd
GET /payments/credit_id=8e8c5921-2892-445f-9f40-e27159d27e4a
Este problema realmente se debe a un diseño irrealista de cómo se va a utilizar el API y a un mal entendimiento de REST. No hay nada que impida a un recurso el “traer” información de otros recursos relacionados en la misma llamada, reduciendo de esta forma la cantidad de solicitudes al API.
GET /clients/636264b1-dc0d-453e-8804-4ac451e1dbd5?include=credits
Simple. Y si además queremos los pagos?
GET /clients/636264b1-dc0d-453e-8804-4ac451e1dbd5?include=credits,payments
O si en lugar de querer obtener más información necesitamos realizar la misma acción a más de un recurso, por ejemplo, eliminar varios pagos.
DELETE /payments/6313ac69-dc0d-45a8-8804-4ac451e1db5c,0b19e3b6-9fae-40e1-a7c2-f2db1cae8a5a
En el peor de los casos dónde si ocupemos varias llamadas consecutivas entonces podemos utilizar del lado del cliente una librería como HTTPX que como se mencionó anteriormente, permite realizar varias llamadas en la misma conexión por periodos cortos, evitando el costoso Handshake.
Con la adopción de HTTP/2 va a ser natural tener conexiones dónde podamos mandar más de una solicitud a la vez al servidor.
Representación de recursos
Ya mencionamos que la representación de recursos de un API consiste de datos y metadatos pero además esa respuesta tiene que ser consistente a través de todos los recursos. Esta consistencia ayuda en la creación y simplificación de clientes que consuman el API.
En Creditar.io la representación de un sólo elemento de tipo cliente se ve así.
GET /clients/636264b1-dc0d-453e-8804-4ac451e1dbd5
{ "data": [
{ "id": "636264b1-dc0d-453e-8804-4ac451e1dbd5", ... }
],
"links": [
{ "rel": "self", "uri": "/clients/636264b1-dc0d-453e-8804-4ac451e1dbd5" }
]
}
Como podemos apreciar la respuesta contiene datos y metadatos. Primeramente data contiene un arreglo con la representación de todos los recursos solicitados, en este caso un sólo elemento.
links contiene información de acciones que podemos realizar sobre los recursos que obtuvimos, además del uri de dónde se realizó la acción. En este caso las uri ayudan a los clientes a no tener que calcularlas para acciones que desee realizar el cliente y además tenemos la confianza de que el uri es correcto y válido.
Si la solicitud fuera para más de un recurso, entonces la representación se vería así.
GET /clients
{ "data": [
{ "id": "636264b1-dc0d-453e-8804-4ac451e1dbd5", ... },
{ "id": "0b19e3b6-9fae-40e1-a7c2-f2db1cae8a5a", ... }
],
"pagination": {
"cursors": {
"after": "0b19e3b6-9fae-40e1-a7c2-f2db1cae8a5a",
"next_uri": "/products?cursor=0b19e3b6-9fae-40e1-a7c2-f2db1cae8a5a"
}
},
"links": [
{ "rel": "self", "uri": "/clients" }
]
}
No cambia mucho respecto a la representación anterior. data tiene un elemento más y en los metadatos tenemos la sección de pagination que contiene información para el cliente pueda hacer solicitudes paginadas al recurso.
Como podemos observar, ambas representaciones son bastante parecidas sin importar que estemos solicitando un elemento o varios de nuestro recurso.
Representación de errores
Hay ocasiones que al solicitar a través del API una acción a un recurso como respuesta obtengamos un error de aplicación. Es importante que el estatus de respuesta sea un error de la serie 4xx, por ejemplo 401 o 422 y no un status de respuesta 200.
Además el status correcto en el cuerpo de la respuesta listar todos los posibles errores en la petición en donde puede venir un tipo de error, un código único del error, un mensaje para el usuario y un link dónde exista más información para el desarrollador que está consumiendo el API.
{
"errors": [
{
"type": "not_found",
"code": "ERR-404",
"message": "El recurso solicitado 636264b1-dc0d-453e-8804-4ac451e1dbd5 no existe",
"href": "staging.creditar.io/api/documentation#err-404"
}
]
}
Es importante que el usuario o el desarrollador pueda obtener toda la información necesaria para solucionar su problema durante el uso de nuestra API.
Compresión de respuestas
El tamaño de la respuesta puede llegar a ser de algunos Kilobytes o más cuando incluye representación de recursos relativamente grandes o bien incluye varios recursos anidados, es posible reducir el tamaño en bytes comprimiendo la respuesta.
Por ejemplo en Rails, podemos utilizar el Middleware Rack::Deflater el cuál soporta el modo de compresión Gzip.
Desde el cliente se envía el Header de HTTP Content-Encoding:"gzip" para indicar que el cliente quiere una respuesta comprimida.
Con el proxy NGNIX es posible configurarlo para que en caso de que nuestro framework no soporte compresión y así delegar esta tarea al proxy.
Ya mencionamos anteriormente que HTTP/2 se comunica con un protocolo binario lo cuál ayudará a reducir el tamaño de las respuestas una vez que su uso sea más común.
Negociación de contenido
Es importante que un API sea explícita en los formatos en que recibe la datos y envía, para esto en HTTP contamos con dos Headers Accept y Content-Type.
Accept es enviado por el cliente para indicar cuáles son los formatos de datos en que puede recibir respuestas, por ejemplo Accept: application/json. Este encabezado le indica al API que esperamos como respuesta un json. Si el servidor no puede darnos la respuesta en el formato solicitado entonces nos enviará un estatus 406 Not Acceptable.
Si el API puede darnos la respuesta en el formato esperado entonces en la respuesta enviará el encabezado Content-Type: application/json.
En el caso de acciones como POST o PATCH en dónde el cliente envía información al API, es importante que el cliente además de enviar el encabezado Accept también envié el encabezado Content-Type para informarle al API cómo debe de interpretar la información que recibe.
Versionado del API
Este es un tema crítico en el desarrollo de API REST. Existen varias opiniones de cómo versionar el API.
Hay quienes dicen que lo mejor es que la versión sea parte de la URI del recurso.
GET /v1/clients
El problema más grande con esto es que si hay una versión 2 entonces hay que ir a cambiar todas las posibles URIs “hardcodeadas” en el cliente. Pero aún si hay un proceso de transición entre 2 versiones del API y se desea utilizar recursos en ambas versiones.
Otra de las opciones es indicar con un parámetro la versión del API.
GET /clients?version=1
Un poco de lo mismo con la solución anterior.
En en caso de Creditar.io se decidió hacer uso de la negociación de contenido, por lo tanto es posible recibir el encabezado Accept: application/vnd.creditar.v1+json para indicar que esperamos un json como respuesta pero además indicar la versión del API que deseamos que responda a nuestra solicitud.
Con esta solución desde el framework para el API podemos hacer que automáticamente otra ruta de código se ejecute cuando se indica la versión 2 del API, sin tener que agregar condicionales o cosas complicadas en el código para mantener las dos versiones activas durante la transición. O bien, si el API versión 2 se ejecuta en otra plataforma diferente desde el proxy es posible inspeccionar el encabezado y dirigir el tráfico a otra aplicación que puede estar escrita en el mismo lenguaje de programación o una diferente.
HATEOAS
HATEOAS o Hypermedia as the Engine of Application State, es una evolución sobre la arquitectura de REST.
Básicamente tiene dos principios: negociación de contenido y controles hypermedia. De ambos ya hablamos en secciones previas. Sobre los controles hypermedia y para que quede claro, no son otra cosa que las posibles acciones que se pueden ejercer sobre un recurso; es una forma de comunicarle al cliente “Me pediste este recurso y aquí está, ahh y si necesitas realizar alguna acción sobre ese recurso o recursos estas son las acciones posibles”. Esta parte la cubrimos con el metadata de la respuesta, específicamente con la sección de links.
En teoría siguiendo los consejos descritos con anterioridad hacen que nuestra API sea HATEOAS sin pensar mucho en este resultado.
RESTful
Podemos decir con certeza que un API que haga uso apropiado del protocolo de HTTP, que exponga los recursos y acciones a través de Endpoints, que utilice de forma apropiada los verbos de HTTP y que exponga los controles de hypermedia es un API RESTful.
Nuevamente, sin pensar en este objetivo, únicamente con el deseo de que nuestra API sea mejor logramos llegar a aquí.
Documentación
No hay un buen API, aunque técnicamente lo sea, si no existe documentación; pero el llevarla a cabo y mantenerla actualizada puede ser tan complicado como hacer el mismo API.
Afortunadamente hay herramientas que pueden ayudar con este trabajo. En Creditar.io utilizamos API Blueprint que es un markdown especializado para describir APIs. El markdown después es procesado para generar la documentación y generar archivos de esquema de JSON que son utilizados para las pruebas automáticas y así asegurarnos que el API es consistente con la documentación.
El siguiente es un ejemplo de cómo se escribe la documentación en el markdown de API Blueprint.
### List Users [GET]
Returns a list of users paginated by the cursor.
+ Parameters
+ cursor: `10` (number, optional) - Cursor value to paginate response.
+ Request (application/json)
+ Headers
Accept: application/vnd.api-test.v1+json
+ Response 200 (application/json)
+ Attributes
+ data (array[User], fixed-type) - Users data.
+ pagination (object, required) - Pagination information.
+ cursors (object, required) - Cursors.
+ after: `10` (number, required) - Cursor for next record to fetch.
+ next_uri: `/users?cursor=5` (string, required) - URI for next page.
+ links (array, fixed-type, required) - Links references.
+ (object)
+ rel: `self` (string, required)
+ uri: `/users` (string, required)
Para más detalles de cómo lo utilizamos en Creditar.io ver el post Keep your API in shape with API Blueprint. La documentación de Creditar.io se puede consultar aquí.
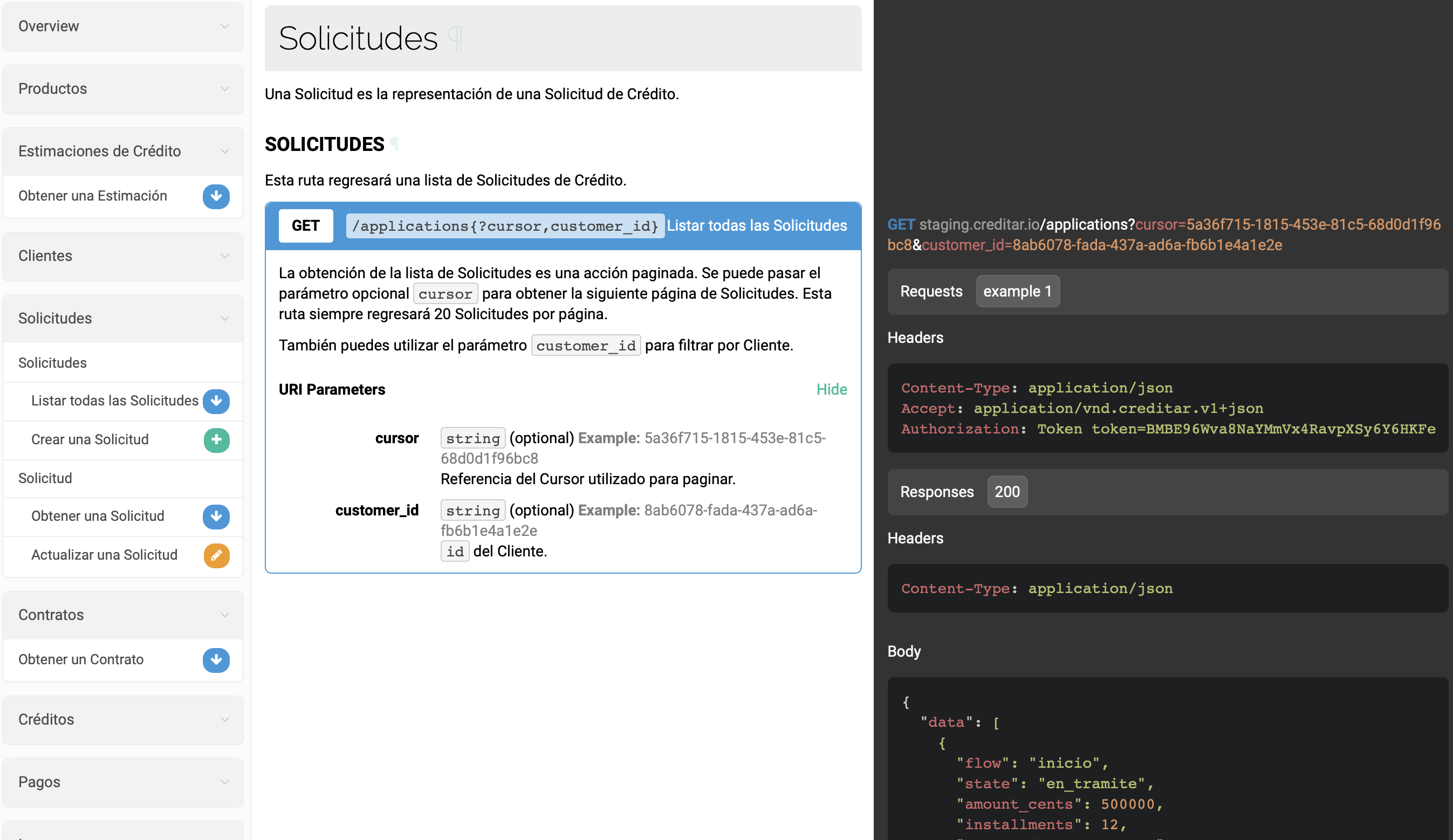
Conclusiones
Para el equipo de Creditar.io es importante que el API funcione y este documentado correctamente, ya que como se mencionó al inicio del post, la idea es que Creditar.io sea una plataforma que se pueda integrar fácilmente en los procesos de las FinTech que lo utilizan.
Afortunadamente los conceptos para tener un API REST saludable no son difíciles de implementar pero si requieren de cierta disciplina.
Espero que los puntos expresados en este post les sirva de ayuda en caso que también estén decidiendo implementar un API y quizás aún no se deciden entre hacerla REST o GraphQL.